I have to start off by saying that this really is a complicated and difficult challenge. But the SRSers rose to the challenge.
Answering this is slightly complicated as well, so I'm going to write this up in two (or three) parts.
Here's installment #1, which is really a story of how to keep digging in, learning things along the way, and finally coming up with something that works.
Entity identification in arbitrary text.
When I sat down to do this Challenge I had an advantage--I already knew about the idea of "entity identification" (aka "named-entity recognition"). The idea is that your computer can scan a text (say, "Around the Equator") and automatically identify named entities--the names of cities, rivers, states, countries, mountain ranges, villages, etc.
Just knowing that this kind of thing exists is a huge help. All I figured I'd need to do is to find such a service and then use it to pull out all of the entities from the text.
My plan at this point was just to filter them by kind, merge duplicates, clean the data a bit, and I'd be done.
But things are never quite this easy.
My first query was for:
[ geo name text entity extraction ]
which leads to a number of online services that will run an entity extractor over the text.
The one I tried first, Alchemy, looks like this:

You can see that I downloaded the fulltext from Gutenberg onto my personal web server (dmrussell.net/docs/Twain-full-text-Equator-book.txt) and handed that link to Alchemy.
I thought that this would be it--that I'd be done in just a few moments. But no. Turns out that you can't just hand Alchemy a giant blob of text (like the entire book), but you have to do it in 50K chunks.
That is, I would have to split up the entire book (Twain-full-text-Equator-book.txt) into a bunch of smaller files, and run those one at a time.
Since the entire book is 1.1Mb, that means I'd have to create 22 separate files, each with 49,999 bytes.
I happen to know that Unix has a command called split that will do that. I used the split command to break it up into 22 files and I moved those all back out to my server.

At this point my natural inclination would be to write a program to call the Alchemy API. The program would basically be something like:
for each file in Twain-Docs:
entities = Alchemy-Api-Extract-Entities( file )
append entities to end of entitiesListFile
Which would give me a big file with all of the entities in it. But I didn't want this to turn into a programming problem, so I looked for a Spreadsheet solution.
Turns out that Google Spreadsheets has a function that lets you do exactly this. You can write this into your spreadsheet cell:
=ImportXML (url, xpath)
where url is the URL of the AlchemyAPI and xpath is an expression that says what you're looking for from the result.
Basically, the url looks like this: (I learned all this by reading the documentation at Alchemy.com)
http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
apikey=XXXXXXXXXX
&url=http://dmrussell.net/docs/Twain-pieces/Twain-part-aa
Let's decrypt this a bit....
The first part: http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
tells Alchemy that I want for it to pull out all of the "RankedNamedEntities" in the text file that follows.
The second part: apikey=XXXXXXXXXX
tells Alchemy what my secret APIKey is. (Note that XXXXXXXXXX is not my API key. You have to fill out the form on Alchemy to get your own. It's free, but it's how they track how many queries you've done.)
The third part: &url=http://dmrussell.net/docs/Twain-pieces/Twain-part-aa
is the name of the file (neatly less than 50K bytes long) that I want it to analyze.
Now, I make a spreadsheet with 22 of these =ImportXML(longURL, xpath)
Here's my spreadsheet (but note that I've hidden my APIKey here).

You can see the "Alchemy base url:" which is the basic part of the call to Alchemy.
The "Composed URL" is the thing we hand to ImportXML. That is, it's basically the:
AlchemyBase + analysisAction + APIkey + baseTextFile
Remember that the spreadsheet function ImportXML takes two arguments--the first is the URL to call Alchemy (which has the link to the file built into it) and an XPath expression.
What's XPath? I did the obvious search to find out....
[ xpath tutorial ]
and found a nice little intro to XPath. Turns out that it's a kind of language for reaching into XML data and pulling out the parts that you want. (It took me about 15 minutes to read up about XPath, and then figure out that all *I* wanted was to pull out the entities from the XML that's being imported. In short, all I needed was the XPath expression: "//entity" as the second argument.
Then, for each of the 22 files I split up from the original text, I created a separate spreadsheet, cell A1 gets the magic ImportXML function. In this case, A1 on spreadsheet A has the ImportXML function that looks like this:
= ImportXML ("http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
apikey=XXXXXXXXX&url=http://dmrussell.net/docs/Twain-pieces/
Twain-part-aa", "//entity")
Here's what the sheets look like after the ImportXML function runs. This is the Alchemy analysis of Twain-part-aa (that is, the first 50K bytes of the book):

Looks pretty good, eh?
I did this same thing 22 times, one analysis for each of the 22 sections of the book (Twain-part-aa through Twain-part-av).
Then I copy/pasted all of the results into a single (new) tab of the spreadsheet. I used paste-special>values so I could then do whatever I wanted with them.
That new page of the spreadsheet looks like this.
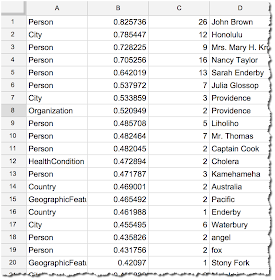
Remember that Alchemy is searching for MANY different kinds of entities (as you can see: HealthCondition, Person, Organization...)
What we want is just the geographic entities. This means I can now use the spreadsheet Filter operation. (Click on cell A1, then click on Data>Filter. It will popup a menu with all of the values you can filter on.)

Here you can see that I've already deselected "Crime"-- so all of the "Crime" entities will be filtered out of the list.
Once I've filtered the list, I'm nearly done. I can selectively filter for only the geographic entities I care about (City, Country, GeographicFeature, StateOrCountry...). And my spreadsheet now looks like this:

This list now has 567 placenames in it, many of which are duplicates. To create a new list of only the unique names, I'll use the =Unique (range) function to create another tab in my spreadsheet with the unique names.
This gives me a sheet that looks like this:

Now we have 283 unique entities.
This column (which I sorted into alphabetic order) looks pretty good, although there are a few oddities in it. ("Ballarat Fly" is an express train to the New Zealand town of Ballarat. And "Bunder Rao Ram Chunder Clam Chowder" isn't a place name, it's just a funny expression that Alchemy Analytics thinks is a place. "Ornithorhynchus" isn't a place, it's the Latin name for a platypus...)
So we still have some data cleaning to do.
But this is point at which we need to do some spot checking to see how accurate the process has been. As is clear, it has included a few extra "place names" that aren't quite right. This is called a "false positive." By my count, the false positive rate is around 3% (that is, out of the 283, I found 8 clear mistakes).
And that makes me wonder, how many "false negatives" are there? That is, how many place names does Alchemy miss?
There's no good way to do this other than by sampling. So I choose a section out of the middle of the text (Twain-part-ak, if you're curious) and manually checked for place names.
I found about a 5% false negative rate as well... (including cities that should have been straightforward, like "Goa"). So this approach could be off by as much as 9 or 10%.
Still, this isn't bad for a first approximation. But there's more work to be done.
In tomorrow's installment, I'll talk about some of the other approaches people used in the Groups discussion. There are always tradeoffs to make in these kinds of situations, and I'll talk about some of those tomorrow as well. Creating a map with all this data? That's Friday's discussion. See you then.
Part 2... tomorrow!
Search on!
Answering this is slightly complicated as well, so I'm going to write this up in two (or three) parts.
Here's installment #1, which is really a story of how to keep digging in, learning things along the way, and finally coming up with something that works.
Entity identification in arbitrary text.
When I sat down to do this Challenge I had an advantage--I already knew about the idea of "entity identification" (aka "named-entity recognition"). The idea is that your computer can scan a text (say, "Around the Equator") and automatically identify named entities--the names of cities, rivers, states, countries, mountain ranges, villages, etc.
Just knowing that this kind of thing exists is a huge help. All I figured I'd need to do is to find such a service and then use it to pull out all of the entities from the text.
My plan at this point was just to filter them by kind, merge duplicates, clean the data a bit, and I'd be done.
But things are never quite this easy.
My first query was for:
[ geo name text entity extraction ]
which leads to a number of online services that will run an entity extractor over the text.
The one I tried first, Alchemy, looks like this:

You can see that I downloaded the fulltext from Gutenberg onto my personal web server (dmrussell.net/docs/Twain-full-text-Equator-book.txt) and handed that link to Alchemy.
I thought that this would be it--that I'd be done in just a few moments. But no. Turns out that you can't just hand Alchemy a giant blob of text (like the entire book), but you have to do it in 50K chunks.
That is, I would have to split up the entire book (Twain-full-text-Equator-book.txt) into a bunch of smaller files, and run those one at a time.
Since the entire book is 1.1Mb, that means I'd have to create 22 separate files, each with 49,999 bytes.
I happen to know that Unix has a command called split that will do that. I used the split command to break it up into 22 files and I moved those all back out to my server.
At this point my natural inclination would be to write a program to call the Alchemy API. The program would basically be something like:
for each file in Twain-Docs:
entities = Alchemy-Api-Extract-Entities( file )
append entities to end of entitiesListFile
Which would give me a big file with all of the entities in it. But I didn't want this to turn into a programming problem, so I looked for a Spreadsheet solution.
Turns out that Google Spreadsheets has a function that lets you do exactly this. You can write this into your spreadsheet cell:
=ImportXML (url, xpath)
where url is the URL of the AlchemyAPI and xpath is an expression that says what you're looking for from the result.
Basically, the url looks like this: (I learned all this by reading the documentation at Alchemy.com)
http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
apikey=XXXXXXXXXX
&url=http://dmrussell.net/docs/Twain-pieces/Twain-part-aa
Let's decrypt this a bit....
The first part: http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
tells Alchemy that I want for it to pull out all of the "RankedNamedEntities" in the text file that follows.
The second part: apikey=XXXXXXXXXX
tells Alchemy what my secret APIKey is. (Note that XXXXXXXXXX is not my API key. You have to fill out the form on Alchemy to get your own. It's free, but it's how they track how many queries you've done.)
The third part: &url=http://dmrussell.net/docs/Twain-pieces/Twain-part-aa
is the name of the file (neatly less than 50K bytes long) that I want it to analyze.
Now, I make a spreadsheet with 22 of these =ImportXML(longURL, xpath)
Here's my spreadsheet (but note that I've hidden my APIKey here).

You can see the "Alchemy base url:" which is the basic part of the call to Alchemy.
The "Composed URL" is the thing we hand to ImportXML. That is, it's basically the:
AlchemyBase + analysisAction + APIkey + baseTextFile
Remember that the spreadsheet function ImportXML takes two arguments--the first is the URL to call Alchemy (which has the link to the file built into it) and an XPath expression.
What's XPath? I did the obvious search to find out....
[ xpath tutorial ]
and found a nice little intro to XPath. Turns out that it's a kind of language for reaching into XML data and pulling out the parts that you want. (It took me about 15 minutes to read up about XPath, and then figure out that all *I* wanted was to pull out the entities from the XML that's being imported. In short, all I needed was the XPath expression: "//entity" as the second argument.
Then, for each of the 22 files I split up from the original text, I created a separate spreadsheet, cell A1 gets the magic ImportXML function. In this case, A1 on spreadsheet A has the ImportXML function that looks like this:
= ImportXML ("http://access.alchemyapi.com/calls/url/URLGetRankedNamedEntities?
apikey=XXXXXXXXX&url=http://dmrussell.net/docs/Twain-pieces/
Twain-part-aa", "//entity")
Here's what the sheets look like after the ImportXML function runs. This is the Alchemy analysis of Twain-part-aa (that is, the first 50K bytes of the book):

Looks pretty good, eh?
I did this same thing 22 times, one analysis for each of the 22 sections of the book (Twain-part-aa through Twain-part-av).
Then I copy/pasted all of the results into a single (new) tab of the spreadsheet. I used paste-special>values so I could then do whatever I wanted with them.
That new page of the spreadsheet looks like this.

Remember that Alchemy is searching for MANY different kinds of entities (as you can see: HealthCondition, Person, Organization...)
What we want is just the geographic entities. This means I can now use the spreadsheet Filter operation. (Click on cell A1, then click on Data>Filter. It will popup a menu with all of the values you can filter on.)

Here you can see that I've already deselected "Crime"-- so all of the "Crime" entities will be filtered out of the list.
Once I've filtered the list, I'm nearly done. I can selectively filter for only the geographic entities I care about (City, Country, GeographicFeature, StateOrCountry...). And my spreadsheet now looks like this:

This list now has 567 placenames in it, many of which are duplicates. To create a new list of only the unique names, I'll use the =Unique (range) function to create another tab in my spreadsheet with the unique names.
This gives me a sheet that looks like this:
Now we have 283 unique entities.
This column (which I sorted into alphabetic order) looks pretty good, although there are a few oddities in it. ("Ballarat Fly" is an express train to the New Zealand town of Ballarat. And "Bunder Rao Ram Chunder Clam Chowder" isn't a place name, it's just a funny expression that Alchemy Analytics thinks is a place. "Ornithorhynchus" isn't a place, it's the Latin name for a platypus...)
So we still have some data cleaning to do.
But this is point at which we need to do some spot checking to see how accurate the process has been. As is clear, it has included a few extra "place names" that aren't quite right. This is called a "false positive." By my count, the false positive rate is around 3% (that is, out of the 283, I found 8 clear mistakes).
And that makes me wonder, how many "false negatives" are there? That is, how many place names does Alchemy miss?
There's no good way to do this other than by sampling. So I choose a section out of the middle of the text (Twain-part-ak, if you're curious) and manually checked for place names.
I found about a 5% false negative rate as well... (including cities that should have been straightforward, like "Goa"). So this approach could be off by as much as 9 or 10%.
Still, this isn't bad for a first approximation. But there's more work to be done.
In tomorrow's installment, I'll talk about some of the other approaches people used in the Groups discussion. There are always tradeoffs to make in these kinds of situations, and I'll talk about some of those tomorrow as well. Creating a map with all this data? That's Friday's discussion. See you then.
Part 2... tomorrow!
Search on!
I have followed along going through the steps & so far I have understood each step. This is quite a challenge for me since I've never worked with API, XML or the more complex steps in Googlesheets. Very educational. Here's my shared sheets created so far
ReplyDeletehttps://docs.google.com/spreadsheets/d/1VJwvt7b9ODsGb4rgrngamODEEoyngbeenugRZTnNnMM/edit?usp=sharing
I have combined the 22 sheets into one by copy & paste values. Was there an action I could have done this in one step? I couldn't find one so I did them one by one.
I've run into a discrepancy that I haven't figured out,yet. I have a total of 1149 lines of data at this stage but yours is 567 lines. Can you see anything glaring that I can't see, yet? Oh I just saw that my rows have the original row number. It's likely caused by how I combined the sheets. Suggestions?
https://docs.google.com/spreadsheets/d/1VJwvt7b9ODsGb4rgrngamODEEoyngbeenugRZTnNnMM/edit?usp=sharing
I had a look to see how many Australian placenames that were listed by Mark Twain would be identified and it was 11 out of 81. Now I'm thinking that with no relative text around the names the API ignored them. Perhaps it doesn't like lists. I wonder if we can reduce the false negatives by amending functions in Alchemy API. I have no idea at the moment how this would be done. Has anyone tried this or have an opinion?
DeleteI am really looking forward to seeing other ways people have tried to solve this challenge. I haven't seen anything posted to groups yet.
Very interesting as always, Dr. Russell. It is good that you post the answer in two or three parts like you are doing. I need to read it slowly and understand each part.
ReplyDeleteTo use the Split command in Unix, how that is done? I'll search the way,and if possible can you explain to me and others than never have used Unix commands?
Hope you feeling better. Looking forward to read and learn with following parts in this Challenge.
Just do a search for [ split Linux command help ] -- that will guide you to tutorials, etc.
DeleteBut just so you'll know, I opened a Terminal window on my Mac, then ran:
split -b 49999 -d Twain-full-text-Equator-book.txt Twain-part-
This splits up the file "Twain-full-text-Equator-book.txt" into pieces that are 49999 bytes (50K - 1) long. They're all names Twain-part-... a, b, c etc..
Thanks, Dr.Russell.
DeleteI did that yesterday after reading the link you provided to us. I didn't know how to run the command. The Terminal window is exactly the answer I needed. I thought maybe you ran in Chrome or Google Drive or other but had no idea. No I know how. Thanks
Hi everyone.
DeleteFirst of all, sorry for the mistake I made in the Answer (Delayed) Post. It is clear the word is Freedom Riders not Raiders. Sorry for that.
On the other hand, I was reading and looking for information in Dr. Russell's SearchResearch Blog this morning and found as always knowledge. I highly recommend these two related to RLBT.
The jonquil glade mystery / how do you know what you know?
On writing good search questions
Searched [split large file windows] to find an alternative to Unix Command Split that Dr. Russell shared with us. There Search Tools and Past Year.
DeleteHow to Split a Large File into Multiple Smaller Pieces
With that we can have the chunks that Dr. Russell mentions in another way. In case Unix is not easy for us.
Hope this helps.
Anne and I took a radically different approach - we went the literary route rather than the mathematical/programming one. While our method might not have worked with more data, we think for this challenge we are going to come up the same or very similar result. We are going to create a spreadsheet this evening and will post. As school librarians we learned some valuable lessons about searching. We tell students to use databases and yet in this challenge the database didn't yield the answer until after we found the reference to the information on Google. Then we went back to the database and were able to get the answer. Google definitely won out in the ease of searching.
ReplyDeleteDebbie -- this sounds really interesting. Can you expand on this? (If you want, go ahead and send me an email with the details. I'm really curious.)
DeleteAnne, Debbie and Dr. Russell, I'm really curious too.
DeleteLooking forward to learn the future posts about this challenge
We posted on the group page. I am hoping that the post went through. If it didn't I'll redo. We have been having wifi problems all day and I am afraid that it may have gotten lost. We used google books and our literary databases to get the info. Let us know if our response isn't on there and will then send via email. It has been one of those days so will not be surprised if our response got lost.
ReplyDeleteWhere is this "group page" that's been mentioned several times (but without any link or pointer, as far as I can tell)?.
DeleteAlmadenmike, the link is in this post. Search challenge (9/3/14): Can you find the places Twain mentions in "Around the Equator"?
Delete"So I set up a Google Group for everyone to discuss this Challenge. For this problem, we can have our discussion in " SRS Discusses Around The Equator.
Thanks, Ramon. Sorry to have missed that link.
Delete