In this week's Challenge ...
I asked two questions that seem different, but are really both examples of web scraping. When I realized they could both be done using the same tool... well, that's too much of a chance to demonstration how to use web scraping in your day-to-day SearchResearch!
I asked these questions which are both "can you grab this data from a web site, and then make these charts?"

In the comments, Ramón got us off to a good start by pointing out that both of these problems required grabbing data from websites, which he pointed out is called "web scraping." That's how I started this Challenge solution as well, by searching for web scraping tools. (I'll write another post about web scraping generally... but this is what I did for this Challenge.)
[ web scraping tool ]
As you can see, there are many, many tools to do this--I just chose the first one, Import.io, as a handy way to scrape the internship data and the Ikea catalog.
Web scraping is just having a program extract data from a web page. In the case of Import.io, you just hand it a URL and it pretty much just hands back a CSV file with the data in it.
So, for the first Challenge (finding cities with internships about "big data" that are in the Bay Area, but not in SF), we first have to find a web site that has internships listed. My query to find them was:
[ summer internships Mountain View ]
Why Mountain View in the query? Because it's pretty centrally located (and it's where I go to work everyday, so I have a local's interest), and I know there are a lot of large companies there with internship possibilities.
Looking at the list of results, I found Indeed.com, Jobs.com, InternMatch.com (and many others).
I decided to scrape the LinkedIn.com listings--again, because they're just down the street, and I happen to known they have a large interest in "big data" topics.
Their jobs site is: www.linkedin.com/job/ -- I just filled out the form for internships near Mountain View on the topic of "big data" and found a nice set of results.

Note that I set the "Location" filter to be "Mountain View" (I could have set it to any city in the Valley).
To scrape this data, I just grab the URL from the page:
https://www.linkedin.com/job/intern-%22big-data%22-jobs-mountain-view-ca/?sort=relevance&page_num=2&trk=jserp_pagination_2
And drop that into Import.IO -- and let it scrape out the data.

At the bottom of the Import.IO page there's a "Download..." option. I saved this data to a CSV file, and then imported that into a Google Spreadsheet, which gave me:

As you probably noticed, this is only 25 positions. I can easily go to the "next page" of results on the LinkedIn site, copy the URL, drop that into Import.IO and repeat. I did this, and appended the results to the bottom of the spreadsheet. (Shared spreadsheet link.)
In the spreadsheet you can see that I copied all of the city names and put them into Sheet 3 ("Cities"). I did a quick cleanup there, and created a second column "CityName" so I could then pull this spreadsheet into a new My Map. But FIRST I copied all of the Cities and CityNames into another spreadsheet with JUST the names of the cities in it. (Why? Because My Maps doesn't like to import spreadsheets with special characters in the columns. A fast workaround is to just make a new sheet with just the data--the city names--that I care about.)
So.. my new (city names only) spreadsheet looks like this:

And when you import that into a My Map, you get this map:

Note that there are many more cities in the spreadsheet than are shown here--there are a lot of duplicates. (I guess we could have looked-up the street addresses for each business, but that's too much like real work.)
And now that you know this method....
doing the Ikea sofas is just as straight-forward.
Go to the Ikea page and search for sofas. Grab the URL and paste into Import.IO -- that gives you another data table. Their URL looks like this:
http://www.ikea.com/us/en/search/?query=sofa&pageNumber=1

Notice that this is page 1 out of 36. It's kind of a hassle to get all 36 (but I'll write up how to do that in another post!), so let's get a few more and do the same "save as CSV."
Luckily, Import.IO has a "Save 5 pages" which automatically grabs the next 5 pages of Ikea data (just by changing the &pageNumber=1 argument in the URL above.
So by the time you save the CSV and import it into your spreadsheet, you'll have 120 rows of data. (For completeness, you could go to page 6, and then import the next 5 pages... but I'm happy with 120 samples of Ikea line of sofas.) Here's my spreadsheet:
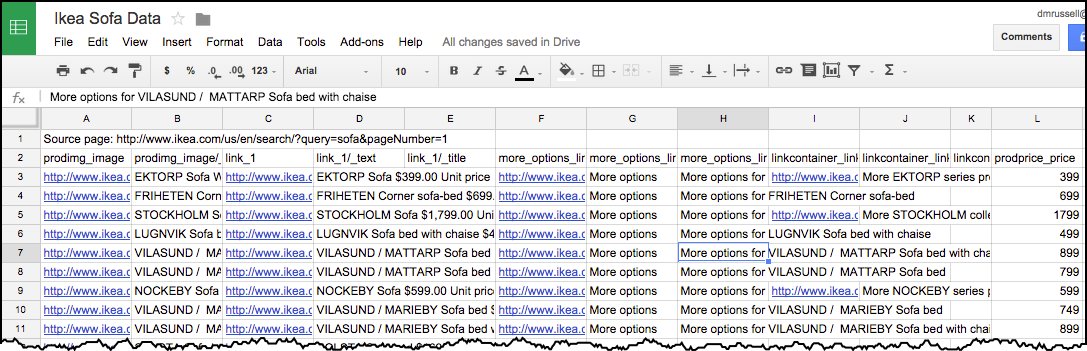
And then you can easily copy out column L (prodprice_price) and do whatever kind of visualization you'd like, including the chart like that above, the chart below, or others:


Search Lessons:
1. Find the right tool. As I've said many times before, often the best way to start a complex project is to figure out what operation you're actually doing. (This particular task is called "web scraping.") And then find a tool that will help you out. In this case, Import.IO is perfect for the task. Be aware that there are many such tools--some of which might be better matches for the task you're doing. (It all depends on the details of what you're trying to do.)
2. Linking tools together. To solve this Challenge, you needed to not just extract the data, but also load it into your favorite spreadsheet, do a bit of cleaning, and then either visualize it with your spreadsheet charting tools, or export/import your data to My Maps (or whatever your intended end goal is).
Hope you enjoyed this Challenge as much as I did!
Search on!
______
Addendum: In response to a couple of questions from readers, I went back and made the map of "big data internships" truly interactive. Now if you click on a pin, you'll see the city, the company with the position, and a link to the job posting.
I asked two questions that seem different, but are really both examples of web scraping. When I realized they could both be done using the same tool... well, that's too much of a chance to demonstration how to use web scraping in your day-to-day SearchResearch!
I asked these questions which are both "can you grab this data from a web site, and then make these charts?"
1. Can you find (or create) a table of 50 summer internship positions in cities that are in Silicon Valley, and not in San Francisco? Ideally, you'd make an interactive map (like the one above), where you can click on the red button and read about the internship.
2. Can you make a chart like this one showing the price distribution of all the sofas in the Ikea catalog? (With the current catalog data.)
In the comments, Ramón got us off to a good start by pointing out that both of these problems required grabbing data from websites, which he pointed out is called "web scraping." That's how I started this Challenge solution as well, by searching for web scraping tools. (I'll write another post about web scraping generally... but this is what I did for this Challenge.)
[ web scraping tool ]
As you can see, there are many, many tools to do this--I just chose the first one, Import.io, as a handy way to scrape the internship data and the Ikea catalog.
Web scraping is just having a program extract data from a web page. In the case of Import.io, you just hand it a URL and it pretty much just hands back a CSV file with the data in it.
So, for the first Challenge (finding cities with internships about "big data" that are in the Bay Area, but not in SF), we first have to find a web site that has internships listed. My query to find them was:
[ summer internships Mountain View ]
Why Mountain View in the query? Because it's pretty centrally located (and it's where I go to work everyday, so I have a local's interest), and I know there are a lot of large companies there with internship possibilities.
Looking at the list of results, I found Indeed.com, Jobs.com, InternMatch.com (and many others).
I decided to scrape the LinkedIn.com listings--again, because they're just down the street, and I happen to known they have a large interest in "big data" topics.
Their jobs site is: www.linkedin.com/job/ -- I just filled out the form for internships near Mountain View on the topic of "big data" and found a nice set of results.
Note that I set the "Location" filter to be "Mountain View" (I could have set it to any city in the Valley).
To scrape this data, I just grab the URL from the page:
https://www.linkedin.com/job/intern-%22big-data%22-jobs-mountain-view-ca/?sort=relevance&page_num=2&trk=jserp_pagination_2
And drop that into Import.IO -- and let it scrape out the data.
At the bottom of the Import.IO page there's a "Download..." option. I saved this data to a CSV file, and then imported that into a Google Spreadsheet, which gave me:
As you probably noticed, this is only 25 positions. I can easily go to the "next page" of results on the LinkedIn site, copy the URL, drop that into Import.IO and repeat. I did this, and appended the results to the bottom of the spreadsheet. (Shared spreadsheet link.)
In the spreadsheet you can see that I copied all of the city names and put them into Sheet 3 ("Cities"). I did a quick cleanup there, and created a second column "CityName" so I could then pull this spreadsheet into a new My Map. But FIRST I copied all of the Cities and CityNames into another spreadsheet with JUST the names of the cities in it. (Why? Because My Maps doesn't like to import spreadsheets with special characters in the columns. A fast workaround is to just make a new sheet with just the data--the city names--that I care about.)
So.. my new (city names only) spreadsheet looks like this:
And when you import that into a My Map, you get this map:
{kind=link}
Note that there are many more cities in the spreadsheet than are shown here--there are a lot of duplicates. (I guess we could have looked-up the street addresses for each business, but that's too much like real work.)
And now that you know this method....
doing the Ikea sofas is just as straight-forward.
Go to the Ikea page and search for sofas. Grab the URL and paste into Import.IO -- that gives you another data table. Their URL looks like this:
http://www.ikea.com/us/en/search/?query=sofa&pageNumber=1
Notice that this is page 1 out of 36. It's kind of a hassle to get all 36 (but I'll write up how to do that in another post!), so let's get a few more and do the same "save as CSV."
Luckily, Import.IO has a "Save 5 pages" which automatically grabs the next 5 pages of Ikea data (just by changing the &pageNumber=1 argument in the URL above.
So by the time you save the CSV and import it into your spreadsheet, you'll have 120 rows of data. (For completeness, you could go to page 6, and then import the next 5 pages... but I'm happy with 120 samples of Ikea line of sofas.) Here's my spreadsheet:
And then you can easily copy out column L (prodprice_price) and do whatever kind of visualization you'd like, including the chart like that above, the chart below, or others:
Such as a histogram of prices (in $150 / bucket price-ranges). You can see here where the bulk of their product lies. Ikea has a target audience in mind, but also carries a few rather expensive items as well.
Search Lessons:
1. Find the right tool. As I've said many times before, often the best way to start a complex project is to figure out what operation you're actually doing. (This particular task is called "web scraping.") And then find a tool that will help you out. In this case, Import.IO is perfect for the task. Be aware that there are many such tools--some of which might be better matches for the task you're doing. (It all depends on the details of what you're trying to do.)
2. Linking tools together. To solve this Challenge, you needed to not just extract the data, but also load it into your favorite spreadsheet, do a bit of cleaning, and then either visualize it with your spreadsheet charting tools, or export/import your data to My Maps (or whatever your intended end goal is).
Hope you enjoyed this Challenge as much as I did!
Search on!
______
Addendum: In response to a couple of questions from readers, I went back and made the map of "big data internships" truly interactive. Now if you click on a pin, you'll see the city, the company with the position, and a link to the job posting.
Dan,
ReplyDeleteI don't get to participate as much in these wonderful search lessons of yours as I want. But I do read them all and save them for later. This one is especially interesting and useful. I just want to say thanks.
Dan,
ReplyDeleteThis time I really don't get it.
For the first challenge you asked for an interactive map ( Ideally, you'd make an interactive map, where you can click on the red button and read about the internship.) but don't give it in your answer although the solution is quite simple.
In the second one you give an answer that completely miss the point, most of the products you show in your list are not sofas but covers, chairs, tables… The first sofa is "LYCKSELE LÖVÅS Sofa bed $199.00 Unit price" and no sofa appears under that $199 price although on the ikea site you can find a $99 sofa. You say "It's kind of a hassle to get all 36 (pages)" but as I said in my answer you just have to add (or change 1 to 0 in your case) &pageNumber=0 at the end of the URL to get all the results on one BIG page (when pagination occurs on a page and you see a page number in the URL, replacing it by 0 often do the trick and gives you all the results, I'm sure you know). It appears that import.io will not like such a big page and ask for downloading their app (I haven't done it yet but will give it a try) hence the use of Openrefine. I really don't understand the use of wrong charts. No data is better that bad data, isn't it?
Anyway thanks for those always interesting challenges.
Philippe
Phillipe -- Well, my map IS interactive, but the pop-up information is pretty sparse. As you point out, it's easy to aggregate the data about a city onto the pin. I should have done that.
DeleteAND... You're absolutely right about the sofa data. Almost everything in my table that's < $100 isn't a sofa, but a funky chair or something related to Ikea sofas. I really should have cleaned the data more carefully. (Mea culpa--I was trying to get the post finished up so I could get to work!)
That's a GREAT observation about changing the pagenumber to 0. I didn't know that. How did you learn about that trick? (I don't think it works in general, so I'm curious how you figured it out.)
Yes, Import.IO has real data size limits--which is why a stand-alone app is sometimes the best way to go.
And while the data has some "additional junk" in it, the overall quality isn't terrible. Some additional filtering has to be done by the human user at the time of reading!
Excellent comments. Thanks very much!
Thanks Dan for the answer. I think I learned the page number trick in Wordpress, where you have an option that allows to choose the number of posts per page and to paginate. If you set that option to 0 you get all the posts on the same page. Whenever I see a pagination appearing in the address bar I use the trick if needed.
DeleteThat's a good trick to know. Thanks.
DeleteBTW, I went back and updated the map so it's really interactive now. I added an addendum to my post:
In response to a couple of questions from readers, I went back and made the map of "big data internships" truly interactive. Now if you click on a pin, you'll see the city, the company with the position, and a link to the job posting.
Hope this is more useful as an example.
Hello Dr. Russell, Passager and everyone.
ReplyDeleteI lke this challenge because I needed this tool and never thought it existed.
Thanks for the trick, Passager. I'll try that. About import, I downloaded the desktop option and signed with Google. For what I saw, no difference from the one that works online. I'll work with it more. Also, as you both mentioned, download sometimes is one page. I changed the searches and found that with that query, you can change 5 pages and increase the number. My query allowed 20 pages to download.
About question 1, I like the answer. I thought maybe one specific page was needed. Also, internships are great. Lots of ways to practice and have a better career. I wish I had some of them.
I am looking forward for the next post about this topic.
Have great weekend everyone.
fwiw… in regard to what passager mentioned about making maps pinpoints interactive, I would point to Rosemary's map in
ReplyDeleteher 2/26/15, 5:50PM post as an example of a higher info content pin pop-up - her map takes some zooming to get started
and the accompanying Fusion table is unfortunately a 404 result — as opposed to passager (Google Fusion Tables product) or Fred's map (My Maps product)
Rosemary's includes live links to the listed internship - something that would be really useful and efficient in reviewing the positions. Clever Rosemary. Just thought that was a nice touch.
Think it illustrates that it still comes down to how - and what - data is used to construct the map - seems the inputs are still best determined by Scott Adams meat-sacks, eh? ;-)
Also have to give DrDan some slack on these challenges - he often ends up trying to cover a lot of ground for an audience of varied experience… and he operates from
a very different knowledge base/starting point than many of his readers and knowing that there are multiple ways the often times non-concrete solution can be arrived at…
all while doing his official Goo job: "anesthesiologist of search" or "search Gurkha"… or something like that.
Google search guru Dan Russell at work…
Just saying highly comprehensive how-to tutorials aren't what these weekly questions are about… imo. Think Dan is just trying to stimulate exploration while creating a catalysis
to support his "sensemaking and information foraging" skill building exercises. As GRayR said, thanks for making the effort Dan… even if the result isn't as perfect or concise
as might be hoped for. They are almost always useful or, at least, entertaining and engaging… hard to do week in and week out.
scraping, not scrapping… meat-sacks of the world comply - or confit, with a nice couscous: Julius Marx
Deletekeep an eye here
need an image update, too sunny
Anne and I thought we had posted but our response never appeared so I must have previewed it and then never published it. One thing we did on the Ikea search was changing the dollar amounts in the search. We limited the search from $100 (changing the bottom number from 0 to $100) to $1975 which was the amount already there. By doing that we eliminated most but not all of the extraneous stuff. There was one couch that was on sale for $167 so we probably could have set the bottom limiter at $150 and not removed any actual couches. This was an interesting search for Anne and me because there were many new terms. We had never heard of big data jobs. Since we are high school educators we should know about what fields of employment are out there for our students. As I had said in my unpublished post, schools are pushing careers in STEM and this might come under the umbrella of T for technology but still I don't think most people outside of Silicon Valley know about this. We certainly didn't and when I've asked around no one else did also. So doing the search on big data jobs which led us to this article in Forbes magazine - http://www.forbes.com/sites/louiscolumbus/2014/12/29/where-big-data-jobs-will-be-in-2015/ - which really gave us a great overview on the topic and showed that the growth in this field is enormous. As always we love these challenges and consider working on them part of our ongoing professional development.
ReplyDeleteClipping off the "obviously not in the sofa price range" data is a good move. If I were going to give this report to my manager, I would have cleaned the data a bit more--and this is a fast way to improve the data quality.
DeleteWRT "big data" -- yeah, it's a thing. I moderated a panel on the future of big data -- the YouTube video is https://www.youtube.com/watch?v=KenqiihxT1U -- my part starts at 10:50, and I moderate the discussion throughout. It's a pretty quick and useful overview of some of the prospects and possibilities for Big Data.
This comment has been removed by the author.
ReplyDelete